Stack Overflow questions around the world
By Julia Silge
April 11, 2018
I am so lucky to work with so many generous, knowledgeable, and amazing people at Stack Overflow, including Ian Allen and Kirti Thorat. Both Ian and Kirti are part of biweekly sessions we have at Stack Overflow where several software developers join me in practicing R, data science, and modeling skills. This morning, the two of them went to a high school outreach event in NYC for students who have been studying computer science, equipped with Stack Overflow ✨ SWAG ✨, some coding activities based on Stack Overflow internal tools and packages, and a Shiny app that I developed to share a bit about who we are and what we do.
The Shiny app was fun to build and the results are interesting, so I thought I would share it here!
Data for the app
The data itself for this app tabulates questions asked on Stack Overflow over the past year, for the top several hundred tags in the top several hundred cities. The way I access this data involves our internal databases, but most of the data for questions and answers on Stack Overflow is public. In my opinion, the easiest way to get it in R is to use Google BigQuery and the bigrquery package.
After I query and aggregate the data I want, it looks like this.
library(tidyverse)
tag_city_questions## # A tibble: 131,801 x 8
## Tag Questions CityName CountryName Percent Latitude Longitude
## <chr> <int> <chr> <chr> <dbl> <dbl> <dbl>
## 1 javascri… 271426 London United King… 0.0420 51.5 -0.126
## 2 python 220745 London United King… 0.0470 51.5 -0.126
## 3 python 220745 New York United Stat… 0.0399 40.7 -74.0
## 4 javascri… 271426 Bengaluru India 0.0314 13.0 77.6
## 5 python 220745 San Franci… United Stat… 0.0375 37.8 -122.
## 6 javascri… 271426 New York United Stat… 0.0305 40.7 -74.0
## 7 java 192107 Bengaluru India 0.0429 13.0 77.6
## 8 c# 139099 London United King… 0.0471 51.5 -0.126
## 9 python 220745 Bengaluru India 0.0286 13.0 77.6
## 10 javascri… 271426 San Franci… United Stat… 0.0233 37.8 -122.
## # ... with 131,791 more rows, and 1 more variable: LeafletPop <chr>This data frame tells us for each tag on Stack Overflow, what is the total number of questions asked in the past year, and then for each city/metro area, what is the percent of that total that came from that city. The other columns (Latitude, Longitude, and LeafletPop) are what we are going to use for some mapping.
For example, we could look at just the R questions.
tag_city_questions %>%
filter(Tag == "r")## # A tibble: 522 x 8
## Tag Questions CityName CountryName Percent Latitude Longitude
## <chr> <int> <chr> <chr> <dbl> <dbl> <dbl>
## 1 r 59856 London United Kingdom 0.0482 51.5 -0.126
## 2 r 59856 New York United States 0.0399 40.7 -74.0
## 3 r 59856 San Francisco United States 0.0273 37.8 -122.
## 4 r 59856 Washington United States 0.0270 38.9 -77.0
## 5 r 59856 Amsterdam Netherlands 0.0249 52.4 4.89
## 6 r 59856 Boston United States 0.0217 42.4 -71.1
## 7 r 59856 Zurich Switzerland 0.0201 47.4 8.55
## 8 r 59856 Paris France 0.0196 48.9 2.35
## 9 r 59856 Bengaluru India 0.0190 13.0 77.6
## 10 r 59856 Toronto Canada 0.0173 43.7 -79.4
## # ... with 512 more rows, and 1 more variable: LeafletPop <chr>These are some of the biggest cities in the world, with the largest developer populations. R is used proportionally more in some places than others, so the rankings of these cities will be different than, say, JavaScript.
Building a Leaflet map
For this app to share with the high school students, we wanted to have an interactive map so I turned to my standard option for that, Leaflet. How do we get started with a non-Shiny Leaflet map?
library(leaflet)
tag_city_questions %>%
filter(Tag == "r") %>%
leaflet(width = "100%") %>%
addProviderTiles("CartoDB.Positron") %>%
setView(lng = -90, lat = 40, zoom = 4) %>%
addCircles(lng = ~Longitude, lat = ~Latitude,
color = NULL,
radius = ~sqrt(Percent) * 5e5, popup = ~LeafletPop,
fillColor = "blue", fillOpacity = 0.7)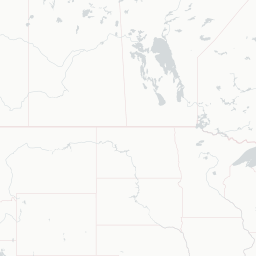
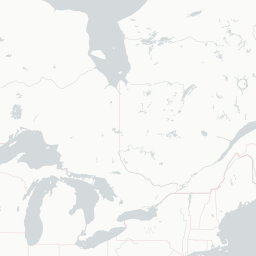
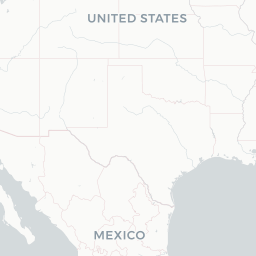
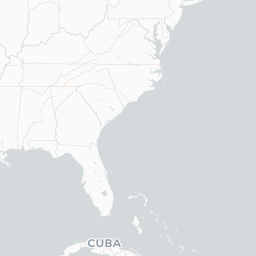


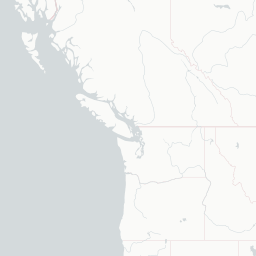
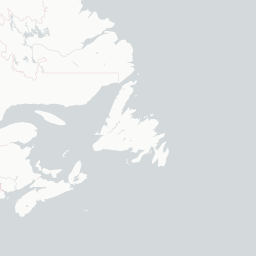
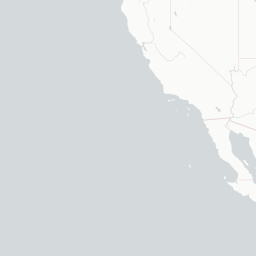







An interactive map! With popup text and everything! But looking at a map like this with only one technology on it isn’t the most informative, because it mostly just shows us where developers live. You know, like that xkcd. What would be more interesting would be to compare multiple technologies at once, to be able to see where technologies are asked about proportionally more and less. To do that, let’s use Shiny.
Building a Shiny app
To make a Leaflet map for Shiny, it’s not too many more steps. The parts of the map that do not need to be redrawn from scratch with every user input go into a call to leafletOutput(), and then the parts of the map that do need to update with user input go into leafletProxy(). After a few more steps, the Shiny app is ready to go!

You can see the code that makes this app by visiting it and clicking on “Source Code” in the upper right.
This is quite interesting now. For example, you can see how anomalous the relative balance of TensorFlow to JavaScript is in the Bay Area compared to most other cities in the US. Lots of other tags to explore too!
One of the best things about working at Stack Overflow is the coworkers I have, and Ian and Kirti are great examples of that. I was really happy to get to help out with their high school coding outreach for this morning, and to build a fun Shiny app to boot. Let me know if you have any feedback or questions!